
Small Models, Big Wins: Using Custom SLMs in Agentic AI
TL;DR
- Most agentic AI workflows consist of chains of narrow, repeatable tasks — using an LLM at every node adds unnecessary latency, cost, and energy use
- Small language models under 10B parameters operate on standard hardware with minimal latency and improved data privacy
- Fine-tuned SLMs can match (or beat) much larger LLMs because they stay within task boundaries
- Modern techniques including synthetic data generation, self-improvement, and knowledge distillation reduce customization requirements
- distil labs provides data-efficient distillation for classification, QA, function calling, and information extraction
- Implement SLMs for specialized tasks, high-throughput applications, and privacy-sensitive scenarios; reserve LLMs for open-ended reasoning
Introduction
Large language models democratized AI feature development — prototyping by prompting an LLM became commonplace and replaced the time-consuming process of creating bespoke machine learning models. This spawned numerous “GPT-wrapper” startups creating agentic systems powered by LLMs.
However, this trajectory toward larger models may not align with actual requirements. We propose combining LLM development speed with machine learning efficiency — offering a more efficient and environmentally sustainable way of designing AI systems.
The Problem: LLMs Are Overkill for Most Agent Nodes
Advanced agentic AI applications decompose into a workflow of specialized, modular tasks: route an intent, extract fields, call a tool, log a result, etc.
Most agent tasks utilize only a very small scope of an LLM’s capabilities, while deploying LLMs at every node incurs penalties in latency, cost, and energy consumption. By contrast, specialized smaller models deliver faster, cheaper performance while enabling design patterns that help us keep our data secure.
The Alternative: Small Language Models
What is a “Small” Language Model?
Models that fit on common consumer hardware for inference. As of 2025, models below 10B parameters are classified as SLMs.
Available SLM families:
- Llama 3 (1B, 3B, 8B)
- Phi-3/Phi-4 (~3.8B, ~7B)
- Qwen2 (0.5B, 1B, 7B)
- SmolLM2 (135M, 360M, 1.7B), SmolLM3 3B
- Gemma (270M, 1B, 2B, 4B, 7B, 9B)
- Mistral (7B)
- Granite (8B)
Are SLMs Good Enough?
Recent NVIDIA research suggests small language models have the right characteristics and sufficient performance to become the backbone of the next generation of agentic AI applications.
When fine-tuned for a single job (e.g., PII redaction, function selection, document classification), SLMs deliver LLM-level accuracy with far lower variance, latency, and cost.
Large models retain advantages in open-ended reasoning and broad synthesis — the mistake is assuming you need that at every node of an agent.
distil labs: SLM Fine-Tuning with Just a Prompt
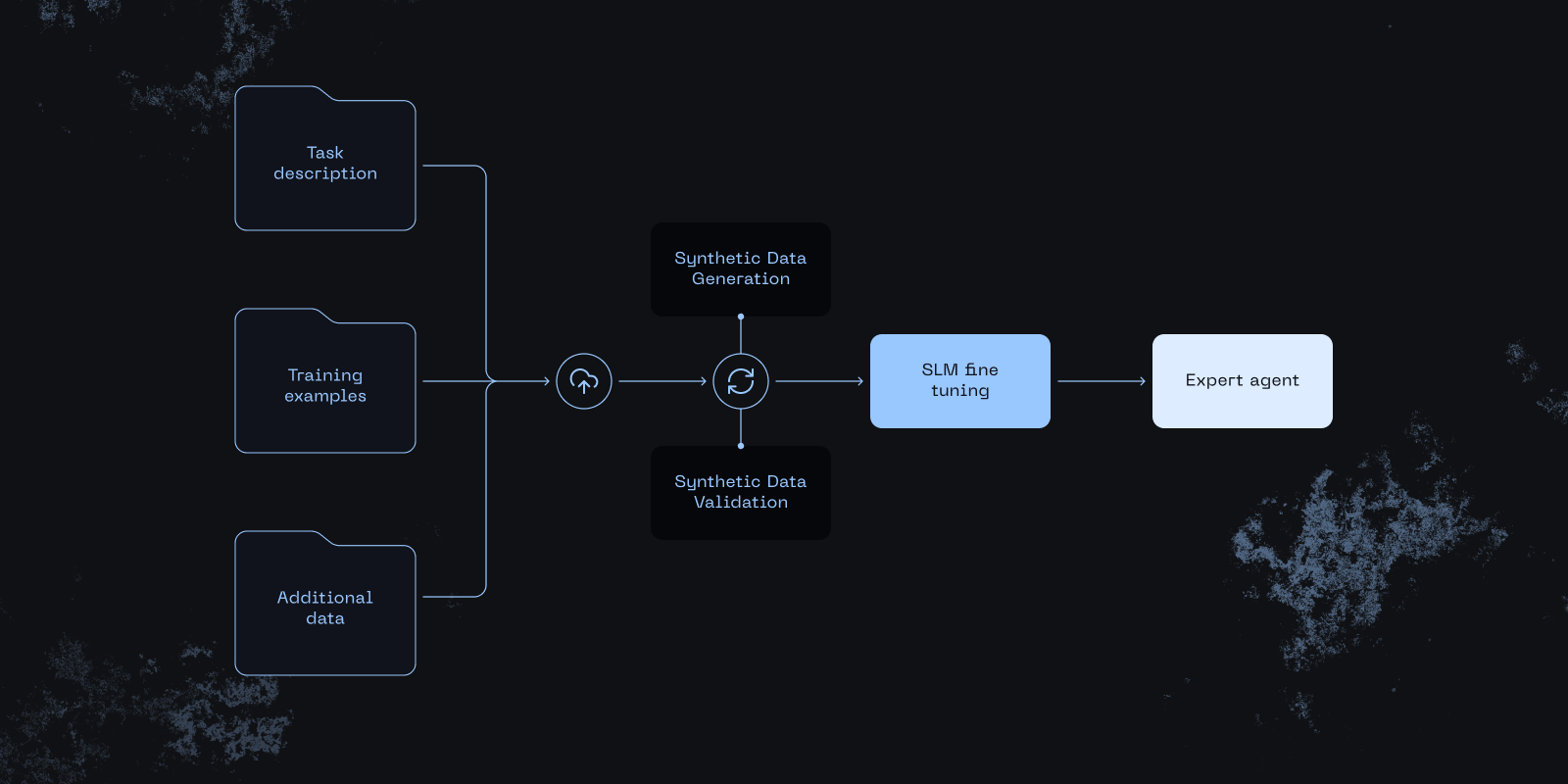
Three steps:
- Write a prompt (optionally attach context data)
- Iterate based on LLM feedback
- Review results within minutes
Prototype with an LLM’s speed, then ship with SLM economics: sub-second latency, lower cost, stricter guardrails, and private-by-default compute.
Supported tasks: classification, open-book QA, closed-book QA, function calling, information extraction.
SLM vs LLM: When to Choose What
| Decision factor | Prefer SLM when… | Prefer LLM when… |
|---|---|---|
| Task complexity | Narrow, well-defined tasks: extraction, tagging, routing, simple Q&A | Open-ended synthesis, multi-step reasoning, planning |
| Knowledge breadth | Domain-specific, templated prompts with clear intent | Broad, cross-domain queries with unclear intent |
| Hallucination tolerance | Strict, deterministic behavior (tool calling, classification) | Some creativity is fine; paired with retrieval/validation |
| Privacy / data residency | Sensitive data, must run on-device/on-prem or in strict VPC | Cloud processing is acceptable |
| Latency | Tight SLAs / near-real-time UX (< ~200 ms) | Seconds are acceptable |
| Cost per request | Ultra-low cost at scale, massive volumes | Higher budget per call acceptable |
| Customization | Model should learn new skills specific to your use case | Satisfied with model accuracy beyond RAG |
| Deployment footprint | Constrained hardware (CPU-only, small edge devices) | Cloud inference or large GPU clusters available |
| Energy / sustainability | Minimizing energy is key | Not the primary constraint |
Common Use Cases for SLMs
Cybersecurity
- Alert/log triage and SIEM/SOAR summary
- Phishing & malware intent classification
- DLP/PII detection at the edge
Financial Services
- KYC/KYB document extraction
- AML alert triage summaries
- Transaction labeling & merchant normalization
Healthcare
- Clinical intake structured field extraction
- On-device dictation cleanup
- Medical documentation information extraction
Insurance
- Claim severity/line-of-business routing
- Policy clause extraction and coverage checks
- Fraud signal pre-screening
Conclusion
Agentic systems don’t need an LLM everywhere. Start with LLMs to explore capabilities, then distill the stable skills into SLMs for each node and keep LLMs only where broad reasoning is essential.
The result: faster, cheaper, greener, and more controllable AI — made practical by data-efficient SLM fine-tuning.
Sources & Further Reading
- Belcak et al., “Small Language Models are the Future of Agentic AI”
- Sudalairaj et al., “LAB: Large-Scale Alignment for ChatBots”
- Wang et al., “Self-Instruct”
- Bai et al., “Constitutional AI”
- Li et al., “Self-Alignment with Instruction Backtranslation”
- Hinton et al., “Distilling the Knowledge in a Neural Network”