Small Expert Agents From 10 Examples
The distil labs platform transforms a prompt and a few dozen examples into a small, accurate expert agent. The process automates data generation, curation, fine-tuning, and evaluation to achieve LLM-level results with models 50-400x smaller.
How It Works
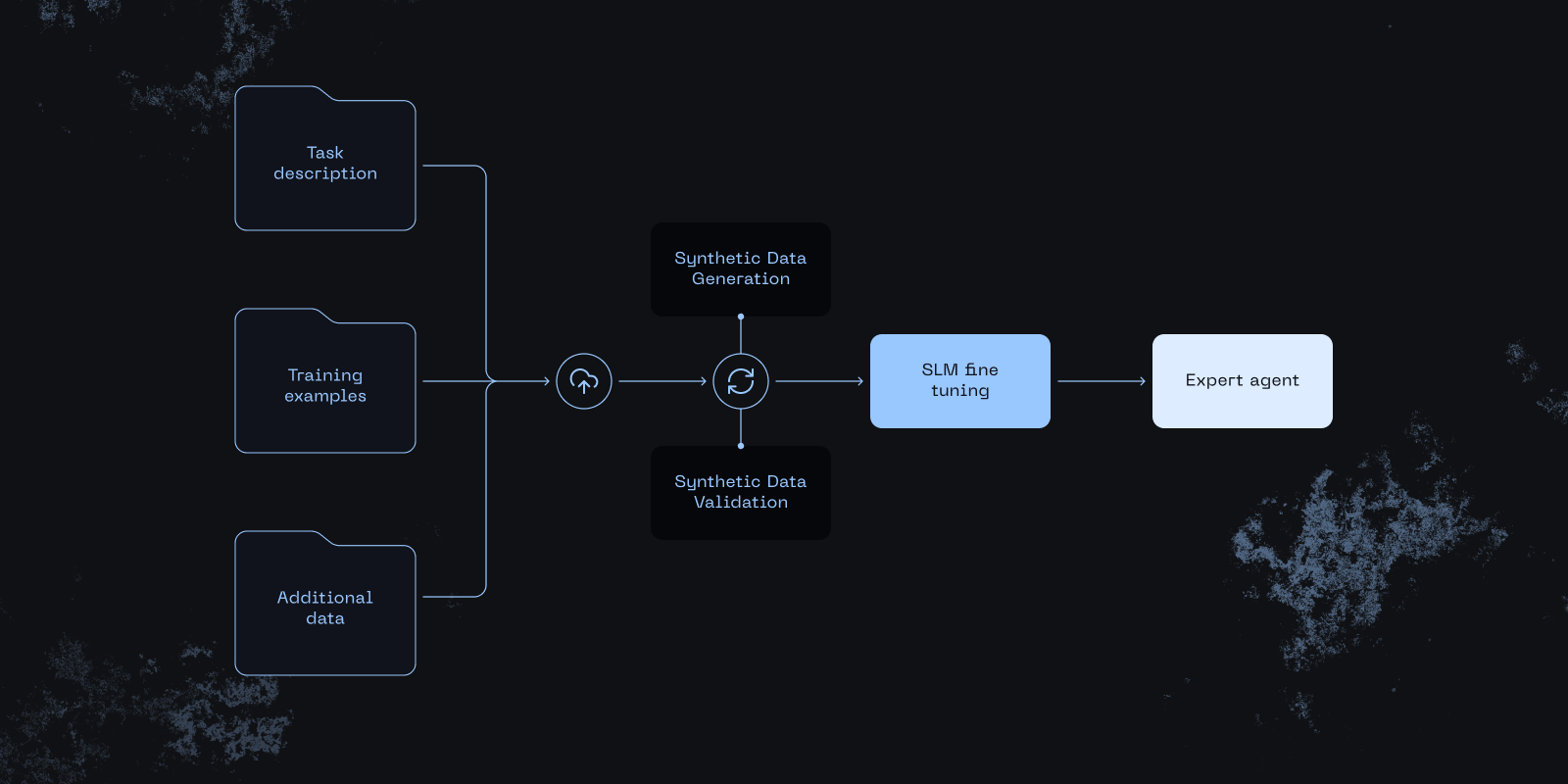
Inputs
- Plain-English task description
- 20-100 labeled examples
- Optional domain-specific documents
Data Generation
An iterative loop: generate synthetic examples using a teacher LLM, then validate using task-specific criteria (length checks, de-duplication, schema validation).
Model Training
Knowledge distillation transfers domain expertise from large teacher models to compact student models.
Example Use Case: PII Redaction
Results
| Dataset | Teacher | Trained Student | Base Student |
|---|---|---|---|
| PII Redaction | 0.85 +/- 0.01 | 0.87 +/- 0.01 | 0.54 +/- 0.03 |
The trained 3B student model outperformed the Llama 70B teacher by 2%, delivering a 150x decrease in inference cost compared to cloud inference.
The Pipeline
- Seed data — Provide a prompt and a small set of labeled examples
- Synthetic generation — Teacher LLM generates thousands of diverse training examples
- Quality curation — Automated filtering removes low-quality, duplicate, or off-task samples
- Fine-tuning — Knowledge distillation trains the compact student model
- Evaluation — Student is benchmarked on held-out test data against teacher performance
Conclusion
With just a prompt and a handful of examples, the distil labs platform creates small expert agents that match or exceed frontier LLM performance on task-specific benchmarks — at a fraction of the cost and with full deployment flexibility.